



Frameworks, core principles and top case studies for SaaS pricing, learnt and refined over 28+ years of SaaS-monetization experience.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
.png)
AI chip shortage


Over the past few weeks, reporting has pointed to a new pinch point in the AI boom: Nvidia is tightening how it allocates its newest AI chips and the high-bandwidth memory (HBM) those chips rely on. HBM is a specialized kind of ultra-fast memory placed right next to the GPU. Think of it as a high-capacity “data pipe” that keeps the chip fed quickly enough to run modern AI.
This matters because when GPUs and HBM are limited, the biggest cloud and data-center buyers get served first. The knock-on effects show up elsewhere: slower availability, tighter limits, and higher costs that can eventually reach consumer devices. That’s why headlines about Nvidia’s shifting priorities and possible gadget price increases have reignited a familiar question: if chips, memory, and infrastructure are getting harder to secure and more expensive, does that mean cheap AI is ending? But the story is broader than Nvidia. Memory supply is tightening across the board-from HBM in AI servers to the everyday memory inside laptops and phones-and prices are rising as manufacturers shift capacity toward AI-focused demand [1][2].
This confluence of factors has sparked broader concerns across the tech industry about stretched supply chains and rising hardware costs, not just for Nvidia’s AI accelerators but across the semiconductor stack. What this really reflects is that the path to widespread, cheap AI will be noisier, slower, and more uneven than many expected. The current moment reflects a mismatch between the speed at which AI software is scaling and the speed at which the physical supply chain beneath it can respond.
To understand how this affects consumers, including subscriptions to large language models and AI-powered apps, it is necessary to look beyond Nvidia headlines and examine where bottlenecks exist across the AI supply chain.
AI doesn’t begin with a GPU and it certainly doesn’t end with a chatbot window. It relies on a long, physical supply chain that moves from the ground to the cloud in a carefully sequenced relay. Understanding where scarcity is emerging requires a quick look at that path.
To understand where today’s AI shortages are actually forming, it helps to walk through the AI stack layer by layer, from the physical world at the bottom to pricing decisions at the top.
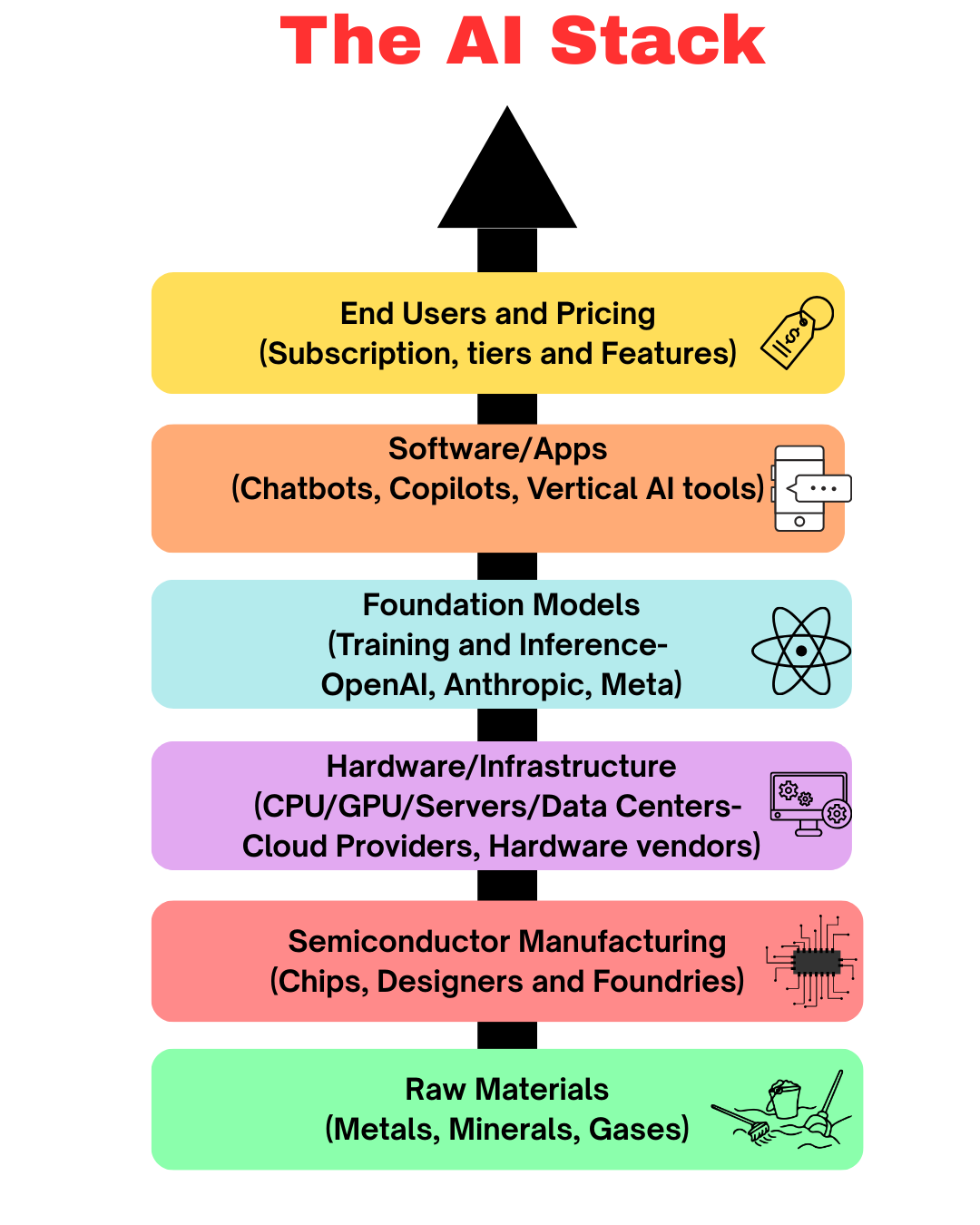
At the base are raw materials: metals, minerals, and specialty gases used to produce semiconductors and memory chips. Constraints here affect both compute and memory supply long before they show up in finished AI systems.
Those materials flow into semiconductor manufacturing, where chips and memory are designed and fabricated. Silicon wafers are thin discs of purified silicon that chips are built on-like the “base sheet” used to manufacture thousands of chips at once. This includes not only GPUs and CPUs, but also DRAM and high-bandwidth memory (HBM). HBM is especially constrained because it requires advanced manufacturing techniques and is produced by only a handful of suppliers, making it one of the hardest components to scale quickly.
Above that sits hardware and infrastructure, where chips are assembled into servers and deployed in data centers. This is where HBM becomes a binding constraint. Modern AI accelerators require large amounts of HBM tightly coupled to the GPU. Even when GPU wafers are available, a lack of HBM or advanced packaging capacity can prevent those chips from being turned into usable AI servers.
Next come foundation models, which depend directly on available hardware and memory. When HBM is scarce, model training and high-throughput inference become more expensive and more limited. Providers respond by rationing access to the most capable models, slowing training cycles, or prioritizing customers with the highest-volume or highest-value workloads.
On top of the models sit software and applications: copilots, chatbots, and vertical AI tools. Memory and compute constraints show up here as rate limits, smaller context windows, slower response times, or restricted access to advanced models, especially during peak demand.
Finally, at the top of the stack are end users and pricing. This is where memory and infrastructure shortages become visible as subscription tiers, usage caps, premium plans, or priority access. What looks like a pricing or packaging choice is often the downstream effect of HBM scarcity and rising memory costs several layers below.
While pressure exists across the AI stack, the primary bottlenecks are not forming at the application or model layer. They’re forming in the middle of the stack-where physical components determine how much AI capacity can actually be built-specifically in (1) memory supply (Semiconductor manufacturing layer) and (2) advanced packaging (Hardware & infrastructure layer).
Memory is the first signal-and it sits in the Semiconductor manufacturing layer. Reuters reports the squeeze now spans “almost every type of memory,” including HBM, and that prices in some segments have more than doubled since February 2025[3]. The same reporting (citing TrendForce) shows how extreme the tightening is: DRAM supplier inventories fell to 2–4 weeks by October 2025, down from 13–17 weeks in late 2024. Pricing confirms this scarcity. Reuters reported Samsung raising certain server-memory prices by 30% to 60%, including 32GB DDR5 modules rising from $149 (September) to $239 (November)[4]. Looking ahead, Counterpoint expects server-memory prices could double by end-2026, implying this isn’t a short-lived blip[5].
Then comes the “make it deployable” choke point-and it lives in Hardware & infrastructure. Even if wafers and memory exist, you still need enough advanced packaging capacity to integrate GPU + HBM into usable accelerators and servers. TrendForce reports TSMC’s CoWoS capacity is effectively fully booked, with expansion taking time-industry estimates suggest scaling from roughly 75,000–80,000 wafers/month today to 120,000–130,000 wafers/month by end-2026. [7].This matters because modern AI accelerators require large amounts of HBM tightly integrated with GPUs; if HBM and packaging are constrained, you end up with fewer usable servers even if upstream fabrication improves.
What this means for consumers of AI and LLM subscriptions
Hardware bottlenecks matter because they push up the cost of GPU-hours and reduce effective capacity. From there, per-token cost, per-inference cost, and subscription packaging become downstream consequences
A useful way to think about the hardware layer is that all of the messy supply-chain detail collapses into a single metric: the all-in cost of running one GPU for one hour.
A helpful public anchor is PyTorch to Atoms’ breakdown of Meta’s 24,576-H100 cluster: $1.689 per H100-hour all-in, with $0.918/hour going to NVIDIA, $0.159/hour to electricity, and $0.214/hour as cost of capital[6].
That breakdown makes sensitivity math easy: NVIDIA’s line item is ~54% of the total. So if memory + packaging tightness pushes up the “hardware-linked” part of the stack:
That’s the cleanest bridge from “mid-stack constraint” to “compute got more expensive.”
Cost per token ∝ (GPU-hour cost) ÷ (tokens per GPU-hour × utilization)
Mid-stack bottlenecks don’t just raise the numerator ($ per GPU-hour). They also hit the denominators: tokens per GPU-hour can fall when memory bandwidth is tight, and utilization can fall when packaging scarcity creates queues and allocation friction. That compounding can outweigh the headline “hardware got more expensive.”
If GPU-hour cost rises ~10–15% and utilization drops modestly from 70% → 60–65% in constrained windows,
Then: 1.12 × (0.70/0.62) ≈ 1.26 → ~+26% higher delivered per-token COGS.
The outcome is the ~26% higher delivered per-token COGS. We already have evidence of a real memory cost shock (Reuters reports Samsung raising some server-memory prices by 30–60%, e.g., 32GB DDR5: $149 → $239) and a real packaging constraint (TrendForce reports CoWoS is effectively fully booked)[7].
For consumer AI subscriptions, a 26% increase in delivered per-token cost does not translate into a 26% subscription price hike, because compute is only part of what a $/month plan pays for. A simple way to size the pressure is to multiply the per-token cost increase by the compute share of the plan’s marginal cost. If compute is roughly 40–50% of the marginal cost for a consumer plan, then a 26% per-token COGS increase implies about ~10–13% margin pressure on the subscription economics.
On a $20/month plan, that’s roughly +$2 to +$2.60/month if a provider chose to pass the cost through directly. In practice, most providers don’t lead with a clean price increase. The more common first move is to adjust entitlements: if per-token costs are up 26%, keeping the same price would require reducing included usage to about 1/1.26 ≈ 0.79-roughly ~21% less included usage-which is why consumers usually experience this period as tighter caps, slower lanes, smaller context windows, and “priority” tiers before they see broad list-price changes.
Despite near-term friction, the long-term direction remains clear. Hardware supply chains eventually respond to price signals. New fabs, expanded packaging facilities, alternative memory technologies, and more efficient chip designs are already underway[8]. As capacity comes online, the marginal cost of running AI models will continue to fall.
At the same time, model efficiency keeps improving. Better architectures, distillation techniques, batching, and inference optimization steadily reduce the compute required per output. Even when hardware prices spike temporarily, software innovation works in the opposite direction.
For consumers, this means that while today’s AI subscriptions may feel constrained or carefully metered, tomorrow’s AI will feel more abundant and embedded. Capabilities that currently justify higher prices will become standard features. What feels like a premium today will feel like baseline functionality a few years from now.
This mirrors earlier cycles in cloud computing and broadband. Early users paid more and accepted limits. Once infrastructure caught up, those constraints faded into the background and pricing shifted toward flat, predictable subscriptions.
How to interpret the current moment
The Nvidia-centric headlines are ultimately a reminder that AI’s trajectory is bounded by physical realities. Software demand is compounding at a rate the hardware supply chain cannot yet match, and whenever those curves diverge, temporary scarcity surfaces as higher infrastructure costs, allocation decisions, and slower deployment cycles. None of this signals a structural reversal in AI’s long-term cost curve - it simply reflects that atoms do not scale with the elasticity of code.
For the broader tech ecosystem, this period should be understood as a recalibration phase. Providers will tighten resource tiers, formalize usage boundaries, sequence model rollouts more deliberately, and adjust pricing where margins are under pressure. At the same time, the quality, efficiency, and reliability of AI systems will continue to improve, driven by architectural progress, inference optimizations, and more capable models emerging from constrained compute budgets.
The destination hasn’t changed. AI is still on a path toward commoditization and broader accessibility. What we are experiencing now is the turbulence that occurs when global supply chains race to catch up with demand that is growing an order of magnitude faster than historical semiconductor cycles. The constraints are real, but they are transitional - and they are shaping, rather than derailing, the next phase of AI deployment across the industry.
Join companies like Zoom, DocuSign, and Twilio using our systematic pricing approach to increase revenue by 12-40% year-over-year.